Zap Web Crawling
Continuando con las funcionalidades de la tool Zed Attack Proxy, que por cierto recienliberado la versión 2.4.1 y pueden actualizar con ctrl+u o “ayuda - comprobar actualizaciones” si es que al abrirlo no les ha ofrecido actualizar,veremos como hacerlo en el acápite respectivo por si quieren tener la ultima versión que esperan para ver primero ello?.
En este capítulo veremos las características de spidering que presenta y sus diferencias.
Que es Crawling o Spidering
Un crawling o spidering es una herramienta, o en éste caso una funcionalidad de Zap, que sirve para identificar los enlaces existentes en un target, de ésta manera llegamos a tener una idea de la manera en la que está compuesta el sitio a analizar e identificar posibles directorios o archivos sensibles que nos pueden ser útiles a la hora de nuestra auditoría.
La forma en la que Zap trabaja es recursiva, es decir que a medida que encuentra nuevos enlaces los va siguiendo, identificando así href, src, http-equiv o location entre otros atributos de html, get y post en lenguajes dinámicos e incluso los vínculos que están escondidos de los bots de indexación en el robots.txt. Esto nos da la posibilidad de hacer el crawling bastante granular, ya que todo es seteable desde las opciones de configuración.
Si vamos a “herramientas - Opciones - Spider”, observamos las características configurables como la cantidad de procesos concurrentes, habilitar/deshabilitar el crawl en la metadata de archivos o en los comentarios del sitio, entre otras opciones.
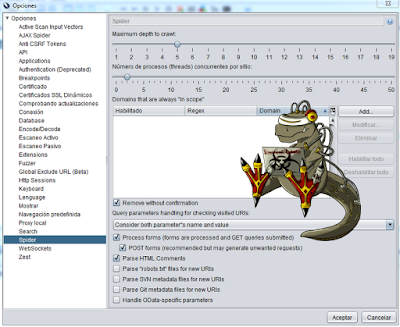
Además de tener la posibilidad de configurar cómo va a ser el spidering, también podemos configurar dónde queremos hacerlo. Partiendo desde una Url target, tenemos cinco métodos para setear el alcance:
- Spider Context: Analizará los enlaces seleccionados dentro del contexto seleccionado, en éste caso, la única opción es 1.
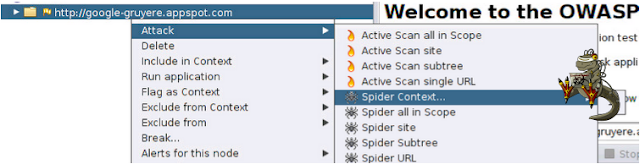
- Spider all in Scope: Analizará lo que le hayamos definido como alcance, en éste caso el alcance es la url principal.
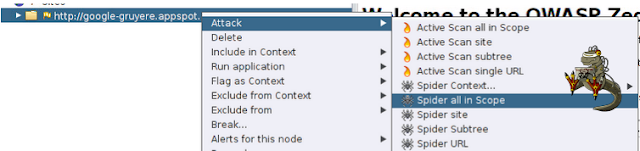
- Spider Site: Hará un crawling por todas los enlaces ya descubiertos en el sitio
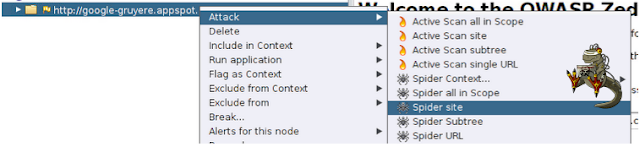
- Spider Subtree: Identificará directorios y subdirectorios dentro del nodo seleccionado.
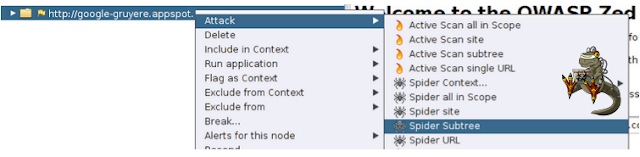
- Spider URL: Analiza todas las urls identificadas y las que se generan a partir de ésta.
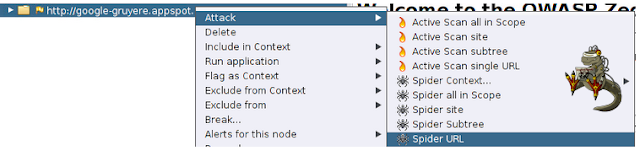
Para comprender mejor las diferencias entre métodos de crawling, les recomiendo ingresar a un sitio con Zap como scanner pasivo (como vimos en el capítulo anterior) y lanzar los cinco métodos diferentes identificando que nos devuelve la ventana de Spider en el panel inferior.